
Este artigo, explana o funcionamento das versões 3 e 4 do YOLO, conforme descrito em artigos científicos, com foco em suas redes neurais, detalhando quais são as camadas ocultas destas duas redes neurais e uma breve descrição de como é o funcionamento dessas camadas.
Alguns dos comportamentos realizados pela rede neural do YOLO v3 e v4 são idênticos ao das suas versões 1 e 2, que serão apresentadas de forma resumida neste artigo, destacando assim as melhorias das versões 3 e 4. Antes de prosseguir, recomendo a leitura dos artigos: YOLO para Detecção de Objetos – Visão Geral e YOLO Versões 1 e 2 (Arquitetura).
Como funciona?
O YOLO utiliza uma rede neural profunda (DNN – Deep Neural Network), rede neural convolucional, cuja a arquitetura é chamada de Darknet, com o mesmo nome do framework utilizado para implantá-la. Sua implementação foi desenvolvida na linguagem C, porém, com a ajuda da comunidade e empresas, já está disponível em várias outras linguagens de programação.
O YOLO cria diversas caixas delimitadoras, para cada caixa é atribuído um valor de confiança, com a porcentagem (0 até 1) de existir um objeto, também é realizada a predição de que tipo de objeto existe na caixa. O valor de confiança para a caixa delimitadora e a predição da classe são combinados em uma pontuação final, que vai informar a probabilidade dessa caixa conter um objeto específico. Por fim, é realizado o processo de supressão não máxima, a fim de “filtrar”/”eliminar” falsos objetos e mesclar regiões de um mesmo objeto [AG].
Nem todo o processo do YOLO é realizado dentro da Rede Neural, como por exemplo, a supressão não máxima, que elimina detecções repetidas de um mesmo objeto, é realizada fora da rede neural. O redimensionamento da imagem também é realizado fora da rede neural, assim como normalizar a quantidade e ordem de canais de cores da imagem.
É Importante lembrar, que atualmente a função de perda, responsável por treinar a rede neural YOLO, faz parte da biblioteca DarkNet, ou seja, independente de qual tecnologia for utilizada para usar o YOLO, será necessária a biblioteca DarkNet para treinar os classificadores.
YOLO V3
Em relação às suas versões anteriores, a versão 3 não possui grandes mudanças segundo o próprio autor, ao mencionar o seguinte texto na introdução do seu artigo YOLO v3: “Consegui fazer algumas melhorias no YOLO. Mas, honestamente, nada como super interessante, apenas um monte de pequenas mudanças que o tornam melhor.”
Uma das principais melhorias no YOLO v3 é o uso de uma nova arquitetura CNN chamada Darknet-53. O Darknet-53 é uma variante com arquitetura ResNet que foi projetada especificamente para tarefas de detecção de objetos. Possui 53 camadas convolucionais, capaz de alcançar melhores precisões na detecção de objetos [KR].
Outra melhoria no YOLO v3 são as caixas de âncora (anchor boxes) com diferentes escalas e proporções. No YOLO v2, as caixas de âncora eram todas do mesmo tamanho, o que limitava a capacidade do algoritmo de detectar objetos de diferentes tamanhos e formas. No YOLO v3, as caixas de âncora são dimensionadas e suas proporções são variadas, para melhor corresponder ao tamanho e à forma dos objetos que estão sendo detectados [KR].
YOLO v3 também introduz o conceito de “redes de pirâmide de recursos” (FPN). FPNs são arquiteturas CNN usadas para detectar objetos em múltiplas escalas. Elas constroem uma pirâmide de mapas de características, com cada nível da pirâmide sendo usado para detectar objetos em uma escala diferente. Isso ajuda a melhorar o desempenho de detecção em objetos pequenos, pois o modelo é capaz de perceber objetos em escalas maiores [KR]. No final deste artigo, o FPN, é melhor descrito.
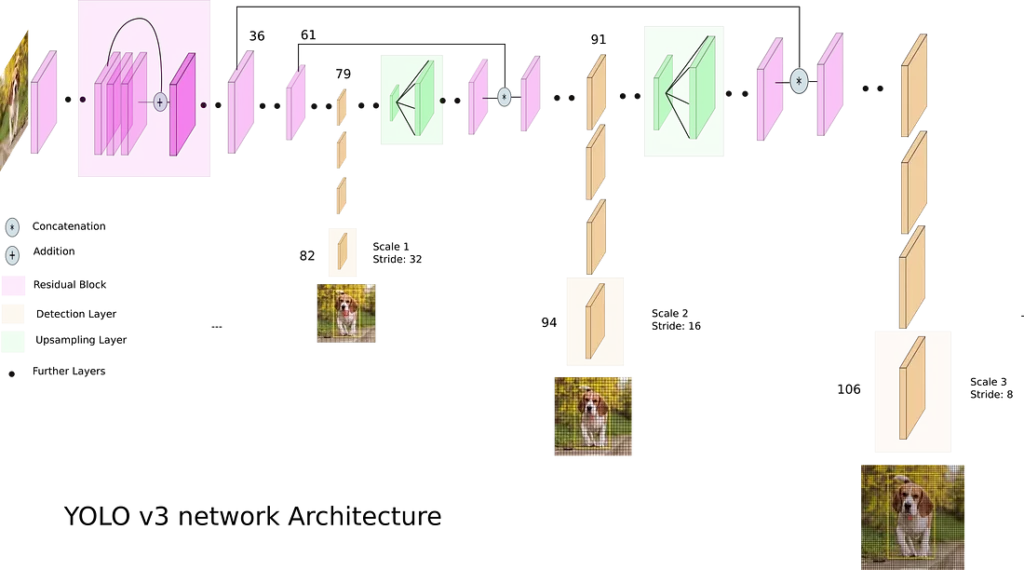
Detecção em três escalas
A arquitetura mais recente possui conexões de salto residuais (ResNet) e aumento da resolução [KA]. Essas conexões de salto permitem que informações de gradiente passem pelas camadas, criando “rodovias” de informações, onde a saída de uma camada/ativação anterior seja adicionada à saída de uma camada mais profunda [DST]. Isto permite que as informações das partes anteriores da rede sejam passadas para as partes mais profundas da rede, ajudando a manter a propagação do sinal mesmo em redes mais profundas. As conexões de salto são um componente crítico que permitiu o treinamento bem-sucedido de redes neurais mais profundas.
Você pode observas nas Figuras 1, os saltos residuais pelas camadas 36 e 61. Note que no final de cada salto existe o simbolo “*”, indicando que as informações do início do salto foram adicionadas (normalizadas) às informações da última camada dentro do bloco.
A característica mais notável da v3 é que ela faz detecções em três escalas diferentes, fornecidas precisamente pela redução da resolução das dimensões da imagem de entrada em 32, 16 e 8, respectivamente. A detecção é feita aplicando kernels de detecção 1 x 1 em mapas de recursos de três tamanhos diferentes em três locais diferentes na rede [KA].
A forma do kernel de detecção do YOLO v3 é 1 x 1 x (B x (5 + C) ), onde B é o número de caixas delimitadoras que uma célula no mapa de recursos pode prever, o “5” corresponde aos 4 primeiros atributos da caixa delimitadora mais a confiança de um objeto, e o C é o número de classes treinadas. Por exemplo, na rede neural YOLO v3 treinado com COCO DataSet, com 3 caixas delimitadoras(B=3) e capacidade pra classificar 80 objetos (C=80), teremos o tamanho de um kernel de 1 x 1 x (3 * (5 + 80)) = 255 [KA].
A primeira detecção é feita pela 82ª camada. Para as primeiras 81 camadas, a imagem é amostrada pela rede, de modo que a 81ª camada tenha um passo(Stride) de filtro de 32. Se tivermos uma imagem de 416 x 416, o mapa de características resultante teria o tamanho de 13 x 13. Uma detecção é feito aqui usando o kernel de detecção 1 x 1, fornecendo um mapa de recursos de detecção de 13 x 13 x 255 [KA].
Em seguida, o mapa de características da camada 79 é submetido a algumas camadas convolucionais antes de ser amostrado em 2x para dimensões de 26 x 26. Este mapa de características é então concatenado em profundidade com o mapa de características da camada 61. Em seguida, os mapas de características combinados são novamente submetidos a algumas camadas convolucionais 1 x 1 para mesclar os recursos da camada anterior (61). Então, a segunda detecção é feita pela 94ª camada, produzindo um mapa de características de detecção de 26 x 26 x 255 [KA].
Um procedimento semelhante é seguido novamente, onde o mapa de características da camada 91 é submetido a algumas camadas convolucionais antes de ser concatenado em profundidade com um mapa de características da camada 36. Como antes, algumas camadas convolucionais 1 x 1 seguem para fundir as informações da anterior camada (36). A terceira e ultima detecção na 106ª camada é realizada, produzindo um mapa de características de tamanho 52 x 52 x 255 [KA].

Cada kernel de detecção corresponde a apenas a um bloco de cada saída do Yolo. Observe na Figura 2, o tensor da primeira saída, onde cada célula da grade 13×13, é responsável por prever 3 caixas delimitadoras, que possuí as informações de suas coordenas, nas suas 4 primeiras posições, seguida da pontuação de confiança (probabilidade da caixa conter um objeto), e uma pontuação de predição para cada classe de objeto treinado.

A mesma estrutura de classificação ocorre na segunda saída, porém agora com uma grade de 26×26, maior que a saída anterior, pois nesta houve um aumento de resolução.

Não diferente das saídas anteriores, ocorre a mesma estrutura de classificação, porém com uma grade de 52×52.
Caixas de âncora
Assim como a versão 2, a versão 3 também usa caixas de âncora. Caixas de âncora são um conjunto de caixas predefinidas com altura e largura específicas; eles atuam como uma estimativa. São múltiplas caixas delimitadoras predefinidas com diferentes proporções e tamanhos centralizados em cada píxel [SA]. As caixas de ancoragem contêm a proporção de determinado objeto conforme ilustrado na Figura 9 e 10.

A versão do YOLO v2 não prevê diretamente as caixas delimitadoras, mas sim as probabilidades que correspondem às caixas âncoras lado a lado, e retorna um conjunto exclusivo de previsões para cada caixa de âncora definida. O uso de caixas de âncora permite que uma rede detecte vários objetos, podendo ser de diferentes escalas ou sobrepostos [DPB].
Para gerar as detecções finais de objetos, as caixas de âncora lado a lado que pertencem à classe de fundo são removidas, e as demais são filtradas por sua pontuação de confiança. As caixas de âncora com a maior pontuação de confiança são selecionadas usando supressão não máxima [DPB].

Mais caixas delimitadoras por imagem
Para uma imagem de entrada do mesmo tamanho, o YOLO v3 prevê mais caixas delimitadoras do que o YOLO v2. Por exemplo, com sua resolução nativa de 416 x 416, o YOLO v2 previu 13 x 13 x 5 = 845 caixas. Em cada célula da grade, 5 caixas foram detectadas utilizando 5 âncoras.
Por outro lado, o YOLO v3 prevê caixas em 3 escalas diferentes. Para a mesma imagem de 416 x 416, o número de caixas previstas é 10.647. Isso significa que o YOLO v3 prevê 10x o número de caixas previstas pelo YOLO v2. Você pode facilmente imaginar por que é mais lento que o YOLO v2. Em cada escala, cada grade pode prever 3 caixas usando 3 âncoras. Como existem três escalas, o número de caixas de ancoragem utilizadas no total é 9, 3 para cada escala [KA].
Remoção da função SoftMax
Anteriormente no YOLO, os autores costumavam suavizar as pontuações da classe e considerar a classe com pontuação máxima, como a classe do objeto contido na caixa delimitadora. Isso foi modificado no YOLO v3 [KA].
As classes Softmaxing baseiam-se na suposição de que as classes são mutuamente exclusivas, ou seja, se um objeto pertence a uma classe, então ele não pode pertencer à outra [KA]. Isso funciona bem para determinadas bases de dados. No entanto, quando temos classes semelhantes, como homem e mulher, em um conjunto de dados, esta suposição falha. Esta é a razão pela qual os autores do YOLO se abstiveram de usar softmaxing nas classes. Em vez disso, cada pontuação de classe é prevista e um limite é usado para prever vários rótulos para um objeto. As classes com pontuação superior a esse limite são atribuídas à caixa [KA].
Diferença da arquitetura YOLO v2 e YOLO v3
Para facilitar o entendimento na mudança de arquitetura do yolo v2 e v3, observe na figura 5, a arquitetura do YOLO v2, descrita no artigo YOLO Versões 1 e 2, ao lado da arquitetura do YOLO v3.

YOLO v4
O YOLO v4, passou a ser desenvolvido por outros desenvolvedores, pois o autor original parou suas pesquisas em visão computacional, devido a percepção do impacto dela na sociedade. Quem assumiu a continuadade do YOLO foram os autores Alexey Bochkovskiy, Chien-Yao Wang e Hong-Yuan Mark Liao.
O objetivo desta versão foi projetar um sistema rápido para funcionar em ambientes produdivos e otimizado para computação paralela, para que qualquer pessoa com uma GPU (Processador gráfico) convencional possa treinar e testar com resultados satisfatórios [ACH].

Podemos dizer que o YOLO v4, em essência, consiste em três pilares principais, o backbone (espinha dorsal) para extração de recursos, o neck (pescoço) focado na agregação de recursos e a head (cabeça) para gerar detecções.
Backbone (Espinha dorsal)
O backbone YOLO é uma pilar de rede neural convolucional que agrupa pixels de imagem para formar recursos em diferentes granularidades. O Backbone normalmente é pré-treinado em um conjunto de dados de classificação, normalmente ImageNet. Backbone é a arquitetura de aprendizagem profunda que atua basicamente como um extrator de recursos. Todos os modelos de backbone são basicamente modelos de classificação.
Três backbones diferentes foram selecionados, durante o estudo do YOLO v4. Após análise rigorosa de diferentes parâmetros em benchmarks padrão, os autores finalizaram o CSPDarknet53 como a espinha dorsal e extrator de características da arquitetura YOLO v4 [ACH].
Neck (Pescoço)
O Neck do YOLO combina e mistura as representações da camada ConvNet antes de passar para o pilar de previsão Head. Neck é um subconjunto do pilar backbone, basicamente coleta mapas de recursos de diferentes estágios do backbone. Em termos simples, é um agregador de recursos.
Neste pilar, os autores acoplaram camadas SPP (Spatial Pyramid Pooling) modificadas para aumentar o campo receptivo da rede, e PAN (Path Aggregation Networks) modificado para melhor concatenação de texturas locais e características globais da CSPDarknet53. No final do artigo, SSP e PAN, são melhor descritos.

Head (Cabeça)
Esta é a parte da rede que faz a caixa delimitadora e a previsão da classe. É guiado pelas três funções de perda YOLO para classe, caixa e objetividade.
Head também é conhecido como detector de objetos, encontra basicamente a região onde o objeto pode estar presente, mas não informa qual objeto está presente naquela região. No YOLO v4, temos detectores de dois estágios e detectores de um estágio, que são subdivididos em detectores baseados em âncora e detectores sem âncora.

Se observar na imagem acima, a versão 4 é bastante semelhante ao YOLO v3. A maior diferença é que CSPDarknet é usado no Backbone e SPP e PANet são usados no Neck, e todo o resto é quase igual. Se você analisar isso com muita profundidade, poderá ver uma pequena diferença, mas no geral, se você entender as três coisas acima corretamente, poderá entender o YOLO v4 [DPB].
Diferença da arquitetura YOLO v3 e YOLO v4
Para facilitar o entendimento na mudança de arquitetura do YOLO v2 e v3, a seguir, a Figura 9 ilustra as duas arquiteturas.

Material Complementar
FPN – Feature Pyramid Networks
Ao fazer previsões para uma escala específica, o FPN aumenta a amostragem (2×) do fluxo descendente anterior e o adiciona à camada vizinha do fluxo ascendente, conforme Figura 11 [ST].
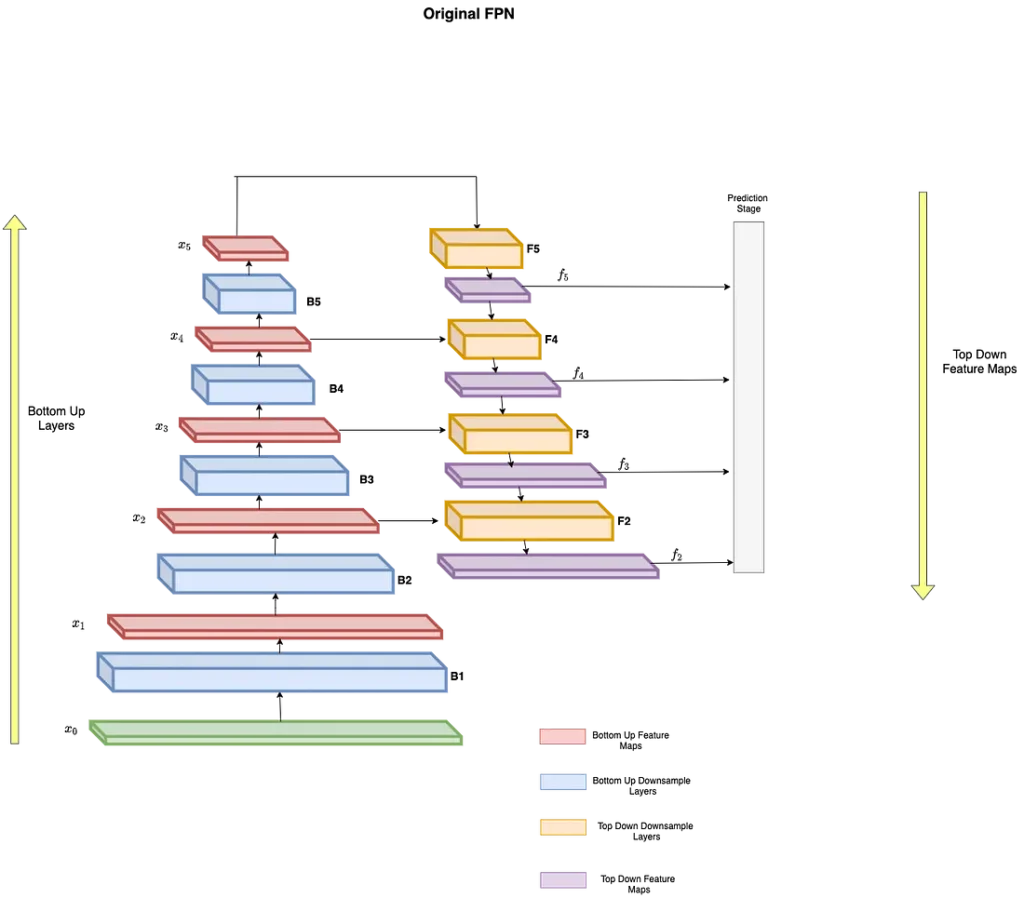
A FPN é composta por um caminho ascendente e descendente. O caminho bottom-up é a rede convolucional usual para extração de características. À medida que subimos, a resolução espacial diminui. Com mais estruturas de alto nível detectadas, o valor semântico de cada camada aumenta [JH].
No caminho de cima para baixo, para construir camadas de resolução mais alta a partir de uma camada semântica rica. Embora as camadas reconstruídas sejam semânticas fortes, as localizações dos objetos não são precisas após toda a redução e aumento da resolução. Para contornar isto, são adicionadas conexões laterais entre as camadas reconstruídas e os mapas de características correspondentes para ajudar o detector a prever melhor a localização [JH].
No YOLOv4, o conceito FPN é gradualmente implementado/substituído pelo SAM, PAN e SPP modificados.
SPP – Spatial Pyramid Pooling
A camada Spatial Pyramid Pooling permite gerar recursos de tamanho fixo, qualquer que seja o tamanho de nossos mapas de recursos. Para gerar um tamanho fixo, ele usará camadas de pooling (exemplo Max Pooling) e gerará diferentes representações dos mapas de recursos.
Observe na figura 10, e suponha que a saída da camada convolicional (parte preta da figura) tenha 256 mapas de recursos.
- Primeiro, cada mapa de características é agrupado para se tornar um valor único (parte cinza). Então, o tamanho do vetor é (1, 256)
- Em seguida, cada mapa de características é agrupado para ter 4 valores (par verde). Então, o tamanho do vetor é (4, 256)
- Da mesma forma, cada recurso é agrupado para ter 16 valores (parte azul). Então, o tamanho do vetor é (16, 256)
- Os 3 vetores criados nas 3 etapas anteriores são então concatenados para formar um vetor de tamanho fixo que será a entrada da próxima camada conectada.

YOLOv4 usa um bloco SPP após CSPDarknet53 para aumentar o campo receptivo e separar os recursos mais importantes do backbone. O pool de pirâmide espacial consiste em pegar uma imagem de entrada e usar camadas convolucionais para extrair seu mapa de recursos, em seguida, usar o pool máximo de tamanho de janela 1 para gerar um conjunto de recursos e, em seguida, usar novamente o pool máximo de tamanho de janela 2. Repetindo este processo n vezes, você terá mapas de recursos de diferentes alturas e larguras, formando uma pirâmide. YOLO v4, em vez de aplicar SPP em uma única camada, divide o recurso ao longo da dimensão de profundidade da rede, aplica SPP em cada parte e, em seguida, combina-o novamente para gerar um mapa de recursos de saída [DPB].
PAN – Path Aggregation Network
O PANet, semelhante ao FPN, segue um caminho ascendente adicional ao caminho descendente seguido pela FPN. Isso ajuda a encurtar esse caminho usando conexões laterais limpas das camadas inferiores às superiores. Isso é chamado de conexão de “atalho”.
Na imagem abaixo, tirada do artigo Path Aggregation Network (PAN), um caminho de baixo para cima (b) é aumentado para tornar as informações da camada inferior mais fáceis de propagar para o topo. Na FPN, a informação espacial localizada viaja para cima na seta vermelha. Não está claramente demonstrado na imagem, mas o caminho vermelho passa por cerca de mais de 100 camadas. O PAN introduziu um caminho de atalho (o caminho verde) que leva apenas cerca de dez camadas para chegar à camada N₅ superior. Esses conceitos de curto-circuito disponibilizam informações localizadas refinadas para as camadas superiores.

PANet convencionalmente adiciona as camadas vizinhas para fazer previsões de máscara usando o pool de recursos adaptativos. No entanto, esta abordagem é ligeiramente distorcida quando o PANet é empregado no YOLOv4, de modo que, em vez de adicionar as camadas vizinhas, uma operação de concatenação é aplicada a elas, o que melhora a precisão das previsões [MR].

Os PANs funcionam de forma semelhante aos FPNs, mas adicionaram um caminho de aumento de baixo para cima, como mostrado na Figura. 12, para que respostas de textura fortes de níveis baixos possam ser fundidas diretamente com respostas semanticamente ricas presentes em N5 usando um caminho de atalho [DPB].
No YOLO v4, o PAN Neck modificado é usado para agregação de recursos. Em vez de adição, a abordagem de concatenação é usada entre cada camada ascendente. Isso ajuda a conservar os recursos perdidos conforme Figura 15.

Referências:
[RJFA] YOLOv3: Redmon, Joseph and Farhadi, Ali, YOLO: An Incremental Improvement. Artigo.
[ACH] Alexey Bochkovskiy; Chien-Yao Wang; Hong-Yuan Mark Liao. YOLOv4: Optimal Speed and Accuracy of Object Detection. Artigo
[KA] Kathuria, Ayoosh What’s new in YOLO v3? Acessado em 09/06/2024
[KR] Kundu, Rohit. YOLO: Algorithm for Object Detection Explained. Acessado em 08/02/2024.
[DPB] Deep Learning Bible. Yolo V1 – EN – Acessado em 15/02/2024.
[DPB2] Deep Learning Bible. Anchor Boxes EN Acessado em 20/03/2024,
[DST] Data Science Team. Uma Visão Geral da ResNet e suas Variantes – Acessado em 15/02/2024
[DPB3] Deep Learning Bible. V4 explicado em todos os detalhes Acessado em 25/03/2024
[SA] Sharma, Aditya. Um detector de objetos melhor, mais rápido e mais forte (YOLOv2). Acessado em 16/09/2023.
[KXSJ] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognitio. Artigo.
[ST] Shreejal Trivedi; DetectoRS — A Comprehensive Review. Acessado em 11/04/2024.
[JH] Jonathan Hui. Understanding Feature Pyramid Networks for object detection (FPN). Acessado em 12/04/2024.
[SLHJJ] Shu Liu; Lu Qi; Haifang Qin; Jianping Shi; Jiaya Jia†; Path Aggregation Network for Instance Segmentation. Artigo.
[MR] Milagre R. PANet: Path Aggregation Network In YOLOv4. Acessado em 12/04/2024.
