
Este artigo, explana o funcionamento das versões 1 e 2 do YOLO, conforme descrito em seus artigos científicos, com foco no detalhamento de suas redes neurais. Detalhando quais são as camadas ocultas destas duas redes neurais e uma breve descrição de como é o funcionamento destas camadas. Uma introdução ao YOLO está disponível em YOLO para Detecção de Objetos – Visão Geral.
Observação: Para melhor entender este artigo e os demais sobre YOLO, é necessário ter uma conhecimento geral sobre inteligência artificial e redesnNeurais.
Antes de detalhar esta rede neural, capaz de detectar diversos objetos em uma imagem, nos próximos 3 parágrafos é apresentado um resumo de seu funcionamento, para melhor entendimento.
Como funciona?
O YOLO utiliza uma rede neural profunda (DNN – Deep Neural Network), uma rede neural convolucional, cuja a arquitetura é chamado de Darknet, com o mesmo nome do framework utilizado para implantá-lo. Sua implementação foi desenvolvida na linguagem C, porém, com a ajuda da comunidade e empresas, já está disponível em várias outras linguagens de programação.
O YOLO cria diversas caixas delimitadoras, para cada caixa é atribuído um valor de confiança, com a porcentagem (0 até 1) de existir um objeto, também é realizada a predição de que tipo de objeto existe na caixa. O valor de confiança para a caixa delimitadora e a predição da classe são combinados em uma pontuação final, que vai informar a probabilidade dessa caixa conter um objeto específico. Por fim, é realizado o processo de supressão não máxima afim de “filtrar”/”eliminar” falsos objetos e mesclar regiões de um mesmo objeto [AG]. Todo esse processo, é realizado dentro da própria rede neural? A resposta é não, nem toda a mágica acontece dentro dela, conforme explicações a seguir.
Nem Tudo é Rede Neural
Apesar da maior parte do processamento ser realizada em uma rede neural, duas etapas de processamento são realizados fora dela: a supressão não máxima e o redimensionamento da imagem para detecção.
A Supressão Não Máxima (Non Maximum Suppression), é uma etapa de pós-processamentos realizado pelo YOLO, por meio de algoritmos especializados. NMS é uma etapa de pós-processamento usada para melhorar a precisão e a eficiência da detecção de objetos. Na detecção de objetos, é comum que várias caixas delimitadoras sejam geradas para um único objeto em uma imagem. Essas caixas delimitadoras podem se sobrepor ou estarem localizadas em posições diferentes, mas todas representam o mesmo objeto. O NMS é usado para identificar e remover caixas delimitadoras redundantes ou incorretas e gerar uma única caixa delimitadora para cada objeto na imagem [KR]. A Figura 1 ilustra o resultado deste processo.

Na outra ponta da rede neural, é realizado um pré-processamento responsável por redimensionar a imagem, a fim de ter exatamente o mesmo tamanho (mesma quantidade de pixeis) que a camada de entrada desta rede neural.
Agora que eliminamos estas duas etapas, ficará menos complexo entender o que acontece dentro do YOLO.
Rede Neural “Dinâmica”
Outro ponto importante a entender é que a Darknet, responsável por treinar a rede neural do YOLO a partir do YOLO 2, também é responsável por dimensionar o tamanho da rede neural, durante seu treinamento, conforme o arquivo de configurações yolo.cfg.
Para se ter ideia, por meio deste arquivo, é possível informar a quantidade de classes que serão treinadas e também a quantidade de filtros que as camadas (layers) CNN possuirão. A modificação destas configurações, alterará a estrutura da rede neural, como a quantidade de layers ocultos e principalmente a quantidade de neurônios de saída.
Entender esse dinamismo, ajuda a entender que o YOLO não é uma rede neural de tamanho fixo e sim uma arquitetura de rede neural que pode ter tamanhos diferentes, para atender diferentes bases de dados com quantidades diferentes de classes.
Função de Perda
Caso você ainda não esteja acostumado a treinar redes neurais e não conhece esse termo, a função de perda (loss-function) ou de custo, tem o objetivo de “levar” o resultado do treinamento em direção à convergência, atuando no processo de ajuste dos pesos da rede neural [GFT]. Em resumo, é a função/cálculo que ajusta os pesos da rede neural.
Esta função é crucial pra treinar qualquer rede neural e cada versão do YOLO possui sua própria função de perda, responsável por treinar a rede. As funções de perda do YOLO fazem parte da Darknet e estão descritas em seus artigos. Podemos dizer, que para utilizar o YOLO com qualquer outra biblioteca (Opencv, OpenVino, Tensorflow, etc), possuímos a dependência da Darknet para treiná-lo.
Mais detalhes sobre cada função de perda serão apresentado nas próximas seções.
YOLO v1
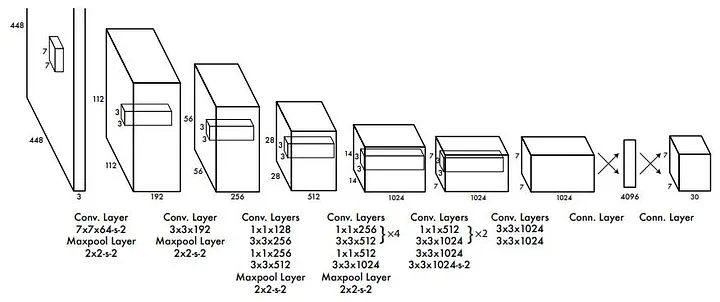
O YOLO v1 é representado na Figura 2, ele consiste em uma rede neural com 24 camadas de convolução (CNN), que atuam como um extrator de características, seguidas por 2 camadas totalmente conectadas, que são responsáveis pela classificação de objetos e regressão de caixas delimitadoras, e a saída final é um tensor de 7 x 7 x 30. Uma breve descrição do comportamento de cada uma das camadas (layer) do YOLO, é apresentada na última sessão deste artigo.
YOLO é uma CNN simples de caminho único e usa convoluções 1×1 seguidas por convoluções 3×3. A ativação Leaky ReLU é usada para todas as camadas, exceto a camada final, em que é usada uma função de ativação linear [TAV]. No final do artigo são apresentadas breves descrições de como funciona cada um destes tipos de camadas.
Podemos dizer que o YOLO, em essência, consiste em três pilares principais, o backbone (espinha dorsal) para extração de recursos, o neck (pescoço) focado na agregação de recursos e a head (cabeça) para gerar detecções. A imagem da Figura 3 ilustra essa ideia, que foi apresentada pelo autor 고민수 em DPB]. Observar essa divisão de estrutura irá ajudar a entender as divisões de detecção do YOLO.

A arquitetura do YOLO v1 não é complicada, na verdade, é apenas um backbone convolucional com duas camadas totalmente conectadas, muito parecido com uma arquitetura de rede de classificação de imagens. A parte inteligente do YOLO (a parte que o torna um detector de objetos) está na interpretação das saídas (head), dessas camadas totalmente conectadas [DPB].
Para fixar ainda mais a estrutura desta rede neural, observe nas imagens 4 e 5, que o fluxo do pilar backbone (espinha dorsal) vai afunilando até uma pequena saída. Este é um processo comum em camadas CNNs, que extraem características ou recursos. Na seção “Camada CNN”, será apresentada uma ferramenta que ilustra os efeitos deste tipo de camada.


Uma nota rápida sobre o backbone (espinha dorsal), é que os autores projetaram seu próprio backbone convolucional inspirado no GoogLeNet [DPB], mas vale ressaltar que é apenas um extrator de recursos.
O pilar seguinte neck (pescoço), é um subconjunto que basicamente coleta mapas funcionais de diferentes estágios do backbone, ou seja, é um coletor de recursos. Estas camadas basicamente transformam os dados de entrada para o pilar head conseguir realizar sua tarefa de detecção de objeto.
Vamos ampliar o último pilar head (cabeça) com um pouco mais de detalhes, nos referindo a ele como tensor de saída. A primeira coisa que você pode notar é que ele é uma camada totalmente conectada, mas com certeza não se parece com uma. Não se deixe enganar pela forma 3D, ela está totalmente conectada, não é produzida por uma convolução, apenas a remodelam, porque é mais fácil de interpretar em 3D. Alternativamente, você pode imaginar e enfileirar o tensor 3D em um longo vetor de comprimento. Seja como for que você imagine, está totalmente conectado, cada neurônio de saída está conectado a cada neurônio, no vetor antes dele [DPB].

Portanto, cada célula é responsável por prever caixas de uma única parte da imagem, mais especificamente, cada célula é responsável por prever com precisão duas caixas para cada parte da imagem. Observe que existem 49 células e cada célula está prevendo duas caixas, então toda a rede irá prever apenas 98 caixas, esse número é fixo.
Para prever uma única caixa, a rede deve gerar uma série de coisas.
- Em primeiro lugar, deve codificar as coordenadas da caixa que o YOLO codifica como (x, y, w, h), onde x e y são o centro da caixa. O YOLO não gera as coordenadas reais da caixa, mas sim as coordenadas parametrizadas. A largura e a altura são normalizadas em relação à largura da imagem, portanto, se a rede gerar um valor de 1,0 para a largura, significa que a caixa deve abranger toda a imagem, da mesma forma, 0,5 significa que é metade da largura da imagem. Observe que a largura e a altura não têm nada a ver com a própria célula da grade, os x ésimos valores são parametrizados em relação à célula da grade, pois eles representam deslocamentos da posição da mesma. A célula da grade tem largura e altura iguais a 1/S. Se a rede gerar um valor de 1,0 para x, isso significa que o valor x da caixa é a posição x da célula da grade, mais a largura da célula da grade [DPB].
- Em segundo lugar, o YOLO também prevê uma pontuação de confiança para cada caixa que representa a probabilidade da caixa conter um objeto.
- Por último, o YOLO prevê uma pontuação (predição) para cada classe treinada, que é representada por um vetor de C valores, e a classe prevista é aquela com o maior valor. Agora, aqui está o problema, o YOLO não prevê uma classe para cada caixa, ele prevê uma classe para cada célula, mas cada célula está associada a duas caixas, portanto essas caixas terão a mesma classe prevista, embora possam ter formas e posições diferentes [DPB].

Os primeiros cinco valores codificam a localização e a confiança da primeira caixa, os próximos cinco codificam a localização e a confiança da próxima caixa e os 20 finais codificam as 20 classes. No total, o tamanho do vetor é 5 X B + C, onde B é o número de caixas, e C é o número de classes.
A maneira como o YOLO realmente prevê as caixas, é prevendo a escala alvo e os valores de desvio para cada precedente, estes são parametrizados pela normalização, largura e altura da imagem. Por exemplo, pegue a célula superior direita destacada no tensor de saída, da Figura 6, esta célula específica corresponde à célula superior direita na imagem de entrada, ela representa uma caixa anterior, que terá largura e altura iguais à largura da imagem dividida por 7 e altura da imagem dividida por 7 respectivamente, sendo a localização no canto superior direito. As saídas desta única célula irão, portanto, deslocar e esticar a caixa precedente para novas posições que, esperançosamente, conterão o objeto [DPB].
Como a célula prevê duas caixas, ela deslocará e ampliará a caixa anterior de duas maneiras diferentes, possivelmente para cobrir dois objetos diferentes (mas ambos são restritos a ter a mesma classe). Você pode se perguntar por que ele está tentando fazer duas caixas, a resposta é porque provavelmente 49 caixas não são suficientes, especialmente quando há muitos objetos próximos uns dos outros, embora o que tende a acontecer durante o treinamento é que as caixas previstas se especializem. Sendo assim, uma caixa pode aprender a encontrar coisas grandes, a outra pode aprender a encontrar coisas pequenas, o que pode ajudar a generalização da rede para outros domínios [DPB].
Como nota final para ajudar no seu aprendizado, é razoável perguntar por que eles não previram uma classe para cada caixa e como seria a saída. Ainda teria 7 x 7 células, mas em vez de cada célula ter tamanho de 5 X B + C, você teria (5 + C) X B. Portanto, para duas caixas, você teria 50 saídas, e não 30. Isso não parece irracional e dá à rede a flexibilidade de prever duas classes diferentes no mesmo local [DPB].
Treinamento YOLO v1
YOLO é treinado de ponta a ponta, com uma arquitetura simples, que significa menos problemas para que coisas dêem errado. Os autores começam pré-treinando sua arquitetura no ImageNet e para fazer isso, eles usam as primeiras 20 camadas convolucionais, seguidas por um pool médio e depois, uma camada totalmente conectada com 1.000 saídas para as 1.000 classes ImageNet. Isso é algo padrão em classificação de imagens e eles afirmam que podem chegar perto da precisão de última geração (para a época) no ImageNet. Lembre-se de que eles estão fazendo isso apenas para pré treiná-lo [DPB].
Eles convertem a arquitetura para detecção de objetos descartando o pool médio e a camada totalmente conectada, adicionam mais algumas camadas convolucionais e configuram as camadas totalmente conectadas conforme descrito acima. A outra coisa que é feita é dobrar o tamanho da entrada, este é um truque comum para detectores de objetos, pois ajuda a ter uma resolução de entrada refinada, especialmente para encontrar objetos pequenos [DPB]. O procedimento de treinamento em si não é notável, a parte inteligente do YOLO está na interpretação dos resultados, nas camadas que destaquei como head e tensor de saída.
O mais interessante do YOLO é a função de perda, que é o método que treina as saídas da rede da maneira que desejarmos, ou seja, responsável por treinar a parte que realiza a detecção de objetos na rede neural. A função de perda do YOLO foram criadas por seus autores. Na Figura 8, segue sua impressão retirada do artigo que deu origem ao YOLO.

De modo geral, o YOLO prevê múltiplas caixas delimitadoras por célula da grade. Para calcular a perda do verdadeiro positivo, é desejado que apenas um delas seja responsável pelo objeto, para tanto, é selecionado aquele com maior IoU (intersecção sobre união) como a verdade fundamental. Esta estratégia leva à especialização entre as previsões da caixa delimitadora, onde cada previsão fica melhor em prever determinado tamanho e proporção.
O artigo Yolo Loss Training e Understanding … YOLOv1 detalham, por partes, a lógica e os cálculos da função de perda do YOLO v1.
YOLO v2
O objetivo do YOLO v2 foi reduzir os erros de localização e ao mesmo tempo superar a precisão da classificação. A ideia de Redmon e Farhadi era desenvolver um detector de objetos que fosse mais preciso que seus antecessores e mais rápido que eles. Porém, construir redes maiores e mais profundas ou reunir várias redes não era o desejado. Em vez disso, com uma abordagem simplificada de arquitetura de rede, eles se concentraram em reunir muitas ideias de outros trabalhos combinadas com suas novas técnicas. Como resultado, melhoraram o desempenho do YOLO em termos de velocidade e precisão [SA2].
A seguir alguns pontos que fizeram a versão 2 ter um desempenho melhor.
Normalização em lote
Foi adicionada uma camada de normalização em lote em todas as camadas convolucionais, que melhorou o mAP em 2% [RJ2]. A normalização ajudou a melhorar a convergência do treinamento da rede e eliminou a necessidade de outras técnicas de regularização, sem que a rede ficasse sobrecarregada com os dados de treinamento [SA2].
Na seção “Material Complementar”, será apresentada uma breve descrição sobre esta técnica.
Caixas de âncora
Uma das principais melhorias no YOLO v2 é o uso de caixas de ancoragem. As caixas âncora são um conjunto de caixas delimitadoras predefinidas com diferentes proporções e escalas. Ao prever caixas delimitadoras, o YOLO v2 usa uma combinação das caixas âncora e os deslocamentos previstos para determinar a caixa delimitadora final, isso permitiu o algoritmo lidar com uma ampla gama de tamanhos de objetos e proporções [KR]. YOLO v1 era um modelo sem âncora que previa as coordenadas das caixas diretamente, usando camadas totalmente conectadas em cada célula da grade [SA2].
Inspirado no Faster-RCNN, que prevê caixas de âncora, conhecidas como caixas B, o YOLO v2 também funciona com o mesmo princípio. Na versão 2 o YOLO remove as camadas totalmente conectadas e usa caixas de âncora para prever caixas delimitadoras, tornando-o totalmente convolucional [SA2].
O que exatamente são caixas de âncora? Caixas de âncora são um conjunto de caixas predefinidas com altura e largura específicas; eles atuam como uma estimativa. São múltiplas caixas delimitadoras predefinidas com diferentes proporções e tamanhos centralizados em cada pixel [SA2]. As caixas de ancoragem contêm a proporção de determinado objeto conforme ilustrado na Figura 9 e 10.

YOLO v2 não prevê diretamente as caixas delimitadoras, mas sim as probabilidades que correspondem às caixas âncora lado a lado, e retorna um conjunto exclusivo de previsões para cada caixa de âncora definida. O uso de caixas de âncora permite que uma rede detecte vários objetos, podendo ser de diferentes escalas ou sobrepostos [DPB].
Para gerar as detecções finais de objetos, as caixas de âncora lado a lado que pertencem à classe de fundo são removidas, e as demais são filtradas por sua pontuação de confiança. As caixas de âncora com a maior pontuação de confiança são selecionadas usando supressão não máxima [DPB].


A Figura 12 ilustra estrutura do Darknet-19, as camadas convolucionais extratoras de características da imagem do YOLO v2.

A Figura 13 mostra a arquitetura de detecção de objetos, com a rede base mostrada no bloco Darknet-19 (pré-treinada com pesos ImageNet) e uma camada de passagem (concatenação) do bloco 5, do Darknet-19, à penúltima camada convolucional, para que o modelo aprenda recursos refinados e tenha um bom desempenho em objetos menores [SA2].


Na camada de saída, da versão 2, foi movida a previsão de classe do nível da célula para o nível da caixa delimitadora. Agora, cada previsão inclui 4 parâmetros para a caixa delimitadora, 1 pontuação de confiança da caixa e 20 probabilidades de classe, ou seja, 5 caixas delimitadoras com 25 parâmetros: 125 parâmetros por célula da grade. Assim como o YOLO v1, a previsão da confiança ainda prevê o IoU da verdade básica e da caixa proposta.
YOLO v2 imprime um mapa de recursos de tamanho 13 x 13. Desta forma, quando o tamanho do mapa de características é pequeno, é fácil prever um objeto grande, mas há um problema porque é difícil prever um objeto pequeno [DPB], como as dimensões espaciais do mapa de características de resolução mais alta, não combinam com o mapa de características de baixa resolução, o mapa de características de alta resolução 26 x 26 x 512 é transformado em 13 x 13 x 2048, que é então concatenado com o original 13 x 13 x 1024 características [SA2].

Para resolver este problema, a versão 2 extrai o mapa de características antes do último agrupamento para obter um mapa de características de tamanho 26 x 26 (x 512). Então, o mapa de características é dividido em 4, mantendo o canal, e então combinado (concatenação) para obter um mapa de características com tamanho de 13 x 13 (x 2048). Adicione isso ao 13 x 13 (x 1024) mapa de recursos para obter um mapa de recursos de tamanho 13 x 13(x 3072) [DPB].
Para facilitar o entendimento, imagine que em vez de ter apenas 2048 característica para analisar cada grade terá 3072 características, unindo o mapa de características de baixa (1024) e alta (2048) resolução.
Treinamento
O treinamento YOLO v2 é composto por 2 fases, onde primeiro é treinada uma rede classificadora como VGG16 e em seguida, substituídas as camadas totalmente conectadas por uma camada de convolução, então o YOLO é treinado novamente de ponta a ponta para a detecção de objetos. O YOLO v2 começa o treinamento com imagens (224 x 224) para o treinamento do classificador, mas depois reajusta o classificador novamente com imagens (448 x 448) usando muito menos épocas, isso facilita o treinamento do detector e aumenta o mAP em 4% [DPB].
Treinamento multiescala
Depois de remover as camadas totalmente conectadas, o YOLO v2 pode capturar imagens de tamanhos diferentes. Se a largura e a altura forem duplicadas, estaremos apenas fazendo 4 x células da grade de saída e portanto, 4 x previsões. Como a rede YOLO reduz a resolução da entrada em 32, só precisamos ter certeza de que a largura e a altura são múltiplos de 32 [SA2].
Para cada 10 lotes, o YOLO v2 seleciona aleatoriamente outro tamanho de imagem para treinar o modelo, isso atua como um aumento de dados e força a rede a prever bem as diferentes dimensões e escalas da imagem de entrada. Além disso, podemos usar imagens de resolução mais baixa para detecção de objetos em detrimento da precisão [DPB].
Este tipo de treinamento permite que a rede faça previsões em diferentes resoluções de imagem. A rede prevê muito mais rápido com entradas de tamanho menor, oferecendo uma compensação entre velocidade e precisão. A entrada de tamanho maior prevê uma previsão relativamente mais lenta em comparação com a menor, mas atinge a precisão máxima [SA2].
A abordagem de treinamento multiescala produziu um aumento de 1,5% no mAP [RJ2].
Diferença Entre YOLO v1 e v2
Na Figura 16, são apresentadas ilustrações das arquiteturas do YOLO v1 e v2 retiradas de Deep Learning Bible, para comparação.

Material Complementar
IoU (Intersection over Union)
IoU é uma métrica crucial para avaliar modelos de segmentação, comumente chamada de Índice de Jaccard, pois quantifica quão bem o modelo pode distinguir objetos de seus planos de fundo em uma imagem. O IoU é usado em inúmeras aplicações de visão computacional, como veículos autônomos, sistemas de segurança e imagens médicas [SD].
Intersecção sobre União é uma métrica popular para medir a precisão da localização e calcular erros de localização em modelos de detecção de objetos. Ele calcula a quantidade de sobreposição entre duas caixas delimitadoras – uma caixa delimitadora prevista e uma caixa delimitadora da verdade básica [SD].
IoU é a razão entre a intersecção das áreas das duas caixas e suas áreas combinadas. A caixa delimitadora da verdade básica e a caixa delimitadora antecipada abrangem a área de união, que é o denominador [SD].

Caso queira entender mais sobre IoU, acesse os artigos Intersection over Union (IoU): Definition, Calculation, Code e IoU (Intersection over Union) and GIoU que detalham até questões de cálculos matemáticos.
Normalização em Lote
“A normalização em lote é um método usado durante o treinamento de redes neurais, onde a camada de entrada é normalizada ou padronizada. Esse processo envolve ajustar e escalar as ativações dos neurônios na rede, garantindo assim que eles tenham uma ativação média de saída zero e um desvio padrão de um. Essa técnica ajuda a reduzir a quantidade de desvio covariante interno, um problema que surge quando a distribuição das ativações da rede muda durante o treinamento” [TS].
Camada CNN – Rede Neural Convolucional
Em resumo, as convoluções funcionam como filtros que enxergam pequenos quadrados e vão percorrendo por toda a imagem captando os traços mais marcantes. O filtro, que também é conhecido por kernel, é formado por pesos inicializados aleatoriamente, atualizando-os a cada nova entrada durante o processo de treinamento.
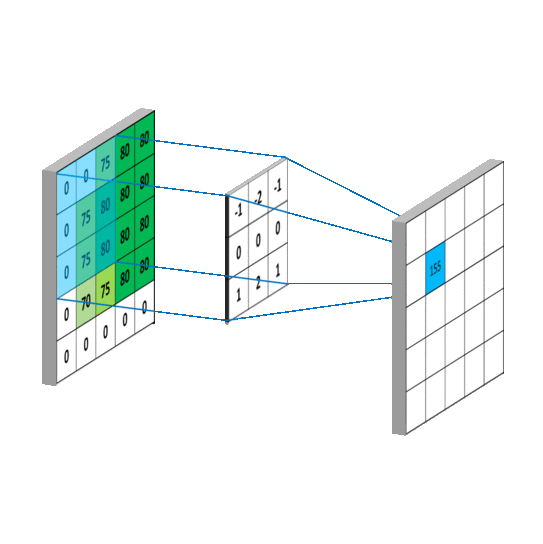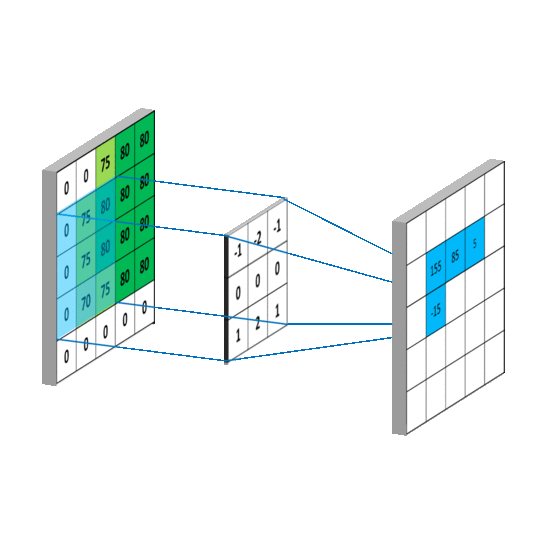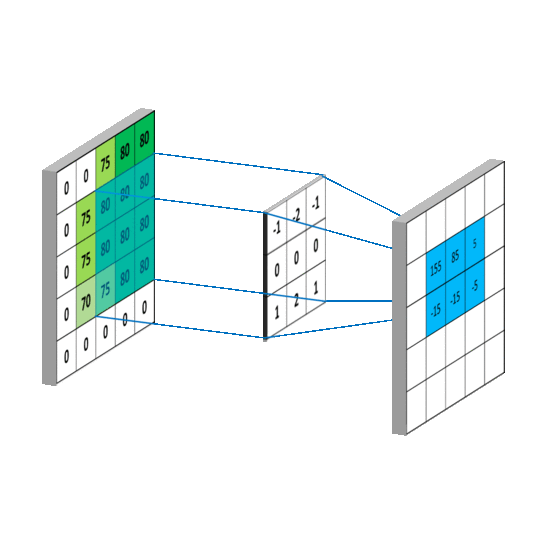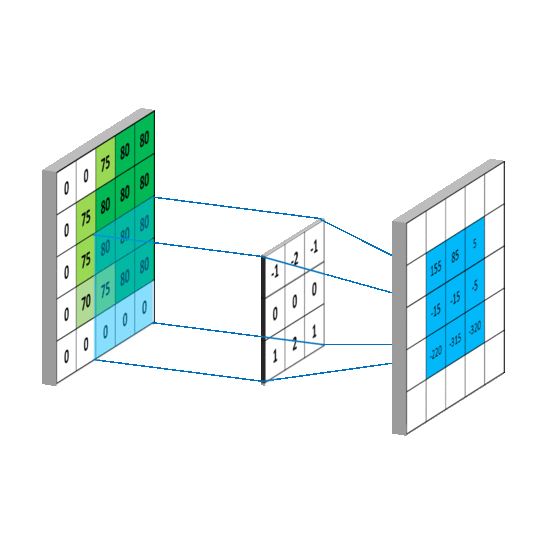
Acesse kernel (núcleo) de processamento de imagens para visualizar alguns efeitos de kernel 3 x 3 e o final da página Image Kernels para reproduzir e simular estes efeitos.
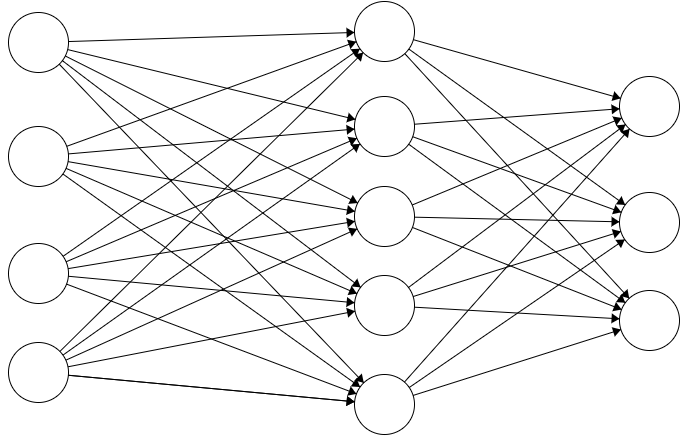
Camada Totalmente Conectada
Como o próprio nome diz a camada totalmente conectada é uma camada, onde cada neurônio é conectado a todos os neurônios da camada anterior.
Referências:
[AG] Alvez, Gabriel. Detecção de Objetos com YOLO – Uma abordagem moderna. Acessado em 15/07/2022.
[RJ1] Redmo, Joseph; Divvala, Santosh; Girshick, Ross; Farhadi, Ali, You Only Look Once: Unified, Real-Time Object Detection. Artigo.
[RJ2] Redmon, Joseph and Farhadi, Ali, YOLO9000: Better, Faster, Stronger. Artigo.
[KR] Kundu, Rohit. YOLO: Algorithm for Object Detection Explained [+Examples]. Acessado em 15/08/2023.
[TAV] Thatte, Abhijit V. Evolution of YOLO — YOLO version 1. Acessado em 15/08/2023.
[HC] Hsin, Carol. Yolo Object Detectors: Final Layers and Loss Functions. Acessado em 23/08/2023.
[GFT] GFT. Função de Perda na Rede Neural. Acessado em 23/08/2023.
[SD] Shah, Deval. Intersection over Union (IoU): Definition, Calculation, Code . Acessado em 23/09/2023.
[SA] Sharma, Aditya. Understanding a Real-Time Object Detection Network: You Only Look Once (YOLOv1). Acessado em 16/09/2023.
[SA2] Sharma, Aditya. Um detector de objetos melhor, mais rápido e mais forte (YOLOv2). Acessado em 16/09/2023.
[TS] TS2. Como a Normalização em Lote de IA Melhora o Treinamento de Redes Neurais. Acessado em 16/09/2023
[DPB] Deep Learning Bible – Yolo V1 – EN – https://wikidocs.net/167699.

