Uma das operações mais importantes em Visão Computacional é a Segmentação. A segmentação de imagens é a tarefa de agrupar partes de uma imagem que pertencem à mesma classe de objeto. Esse processo também é chamado de classificação em nível de pixel. Em outras palavras, envolve o particionamento de imagens (ou quadros de vídeo) em vários segmentos ou objetos.
A operação de segmentação de imagens pode ser facilmente confundida pelas duas operações: identificação de objetos e regiões, e classificação e rotulação. A primeira operação busca extrair objeto da imagem sem saber o que ele é necessariamente, e a segunda classificar o tipo de objeto e região, saber o que é determinado elemento, a quem pertence o tipo do elemento identificado através de rótulos nomeados.

Para entender melhor estas operações, vamos analisar cenários diferentes e posteriormente mencionar algumas técnicas conhecidas para cada tipo de operação.
Cenário 1 e 2 – Detectar objetos e regiões em veículos autônomos
Neste primeiro cenário, explanamos um dos vários problemas que os veículos autônomos precisam lidar, que é segregar/separar a imagem em regiões ou objetos detectados, porém sem a necessidade de saber o que eles são. Esta operação é necessária para que o veículo saiba todos os obstáculos que estão em seu caminho, se possui chão a sua frente ou uma parede, e assim saber como ele pode se descolocar no ambiente.
A grande características desta operação, é que não se precisa saber neste momento, o que é determinada coisa a sua frente, se o elemento é um carro, uma pessoa, uma placa, um poste, um semáforo ou uma moto, por exemplo. Mas sim, saber que existe objetos e regiões, e saber onde estão.
Este tipo de operação é denominado de segmentação de imagem, que consiste em separar a imagem em regiões de interesse com o objetivo de simplificar e/ou mudar a representação de uma imagem para facilitar a sua análise.
Neste cenário, com a segmentação de imagem, o veículo autônomo ao se mover pode monitorar essas regiões e: verificar se são objetos fixos ou se estão se movendo; se estão se movendo e para qual direção estão se deslocando; e identificar se os objetos irão colidir com o veículo.
Uma outra utilidade, para este tipo de operação, é possibilitar separar o solo da imagem para posteriormente analisá-lo, a fim de saber se é uma estrada ou calçada, se é subida ou descida, se é chão de barro ou asfalto.
Para ilustrar este cenário, observe a imagem abaixo com uma segmentação de imagem. Existem diversas técnicas de segmentação e essas técnicas que detectam varias regiões, geralmente não agrupam por tipo de objeto, como foi realizado abaixo. Geralmente são grupos desconexos e não rotulados (sem classificação), porém, na imagem abaixo, os grupos foram rotulados apenas para facilitar o entendimento.

No segundo cenário, continuamos com o exemplo do veículo autônomo, porém, agora vamos analisar as situações em que precisamos identificar e rotular quais são os tipos de objetos a frente do veículo.
Sendo assim, digamos que o veículo precise identificar quais sinais de trânsito estão a sua frente, quais carros e pessoas. Esta operação é denominada de classificação e rotulação, e o resultado esperado é a extração de determinados tipos de objetos, qual sua localização e identificação.
É imprescindível identificar, neste cenário, o que é determinado objeto para a tomada de decisões especiais, por exemplo, ao identificar uma placa de proibido virar a direita, o veículo deve saber que não poderá virar a direita, ao identificar um semáforo, saber se pode ou não prosseguir e se identificar veículos, pessoas ou outros seres, aumentar toda a segurança para não colidir com estes.

Cenário 3 – Detectar documento para realinhamento
Em um cenário mais simples e controlado, digamos que precisamos extrair da imagem a região com determinado documento e identificar suas bordas para realizar alguma técnica de alinhamento.
Neste caso, podemos converter a imagem em tons de cinza, detectar as bordas e linhas retas com técnicas de visão computacional e procurar por regiões retangulares para realizar uma extração do documento da imagem.
As técnicas que detectam bordas e linhas retas, são técnicas de segmentação de imagem.

Cenário 4 – Detectar rostos e realizar reconhecimento facial
Em nosso último cenário, vamos analisar superficialmente um sistema de portaria eletrônica com reconhecimento facial, que habilita a entrada de pessoas em seu apartamento. Neste tipo de sistema é preciso realizar ao menos duas etapas de classificação de imagem.
A primeira etapa necessária é a detecção de rostos na imagem ou câmera digital e segmentação da imagem em subimagens, apenas com os rostos. Este tipo de operação é realizada em tempo real, onde o sistema fica monitorando toda a movimentação da câmera com o objetivo de identificar rostos na imagem, sem a necessidade de saber quem é a pessoa, apenas procurando por rostos.
A segunda etapa a ser realizada, é feita após a identificação do rosto, onde o sistema irá comparar se o rosto identificado é de alguém habilitado a entrar no apartamento e então liberar o acesso. A imagem abaixo busca ilustrar esses dois tipos de problemas de classificação.

Apesar dessas duas etapas serem operações de classificação de imagem, seus objetivos são muito diferentes e para cada uma delas existem soluções diferentes. Para a primeira técnica, a de detecção, existem diversas soluções genéricas capazes de identificar determinado tipo de informação na imagem. Porém na segunda, a de reconhecimento, que exige uma precisão maior, geralmente precisa de uma solução específica para cada situação.
Segmentação de imagem
A segmentação tem como objetivo dividir uma imagem em regiões ou objetos que a compõem. O nível de detalhe, que a divisão é realizada, depende do tipo de problema a ser resolvido. Em resumo, a segmentação deve parar quando os objetos e regiões são encontrados [GW].
A segmentação de imagens não triviais (não obvias), é uma das tarefas mais difíceis no processamento de imagens. A precisão da segmentação que identifique corretamente a localização, a forma dos objetos, a topologia é fundamental para o sucesso final dos procedimentos de análise computadorizadas [GW].
A seguir são apresentadas as principais técnicas de segmentação de imagens, baseadas nos valores de intensidade dos pixels da imagem, com ênfase nas técnicas de detecção de descontinuidades, gradiente, limiarização, identificação de regiões e classificadores.
Detecção de Descontinuidades
Este tipo de técnica particiona a imagem a partir de alterações bruscas nas intensidades de imagens, como pontos, linhas bordas e junções. Uma maneira comum de identificação de descontinuidade, é por meio de aplicações de uma máscara por uma convolução espacial [PS].
Esta técnica analisa a variação de intensidade utilizando uma única camada de cor da imagem, geralmente uma camada em tons de cinza da imagem. Porém, a análise pode ser feita através da representação de uma das cores da imagem, da iluminação, do brilho ou da saturação da imagem.
Observe na Figura 4, a representação A e B das variações de intensidade dos tons de cinza, note que na representação A a mudança de tons de cinza é muito mais abrupta que a representação B. É com base na análise deste variação abrupta que as técnicas de segmentação de imagem por descontinuidade funcionam.

Veja na Figura 5 a aplicação desta técnica, ao aplicar o operador Laplaciano em duas imagens em tons de cinza. Com uma simples técnica de convolução foi possível detectar as bordas de uma imagem.

Gradiente e Bordas
Existem diversas outras técnicas e também operadores capazes de detectar/destacar melhor as bordas em imagens como exemplo, Sobel, Roberts e Canny, e são conhecidos como operações de gradiente, pois realçam a maior variação de gradiente na imagem. Porém, são menos simples de aplicar e realizam operações de derivadas.
Observe na Figura 6 o resultado da aplicação do filtro Sobel na imagem e como ele destacou as bordas na imagem.

Limiarização
Limiarização é um processo de segmentação de imagens que se baseia na diferença dos níveis de cinza, que compõe diferentes regiões de uma imagem. A partir de uma limiar definida a imagem é separada em 2 grupos.
A técnica mais simples de limiarização, consiste em varrer cada pixel da imagem e verificar se o valor do pixel é maior ou menor que uma limiar preestabelecida e gerar uma nova imagem com apenas duas cores. A Figura 7 ilustra a aplicação de uma limiarização simples, com uma limiar de 100.

Existem muitas técnicas de limiarização e todas elas utilizam o histograma da imagem como tomada de decisão. Entre as técnicas mais conhecidas estão o método de Otsu, o método de Seleção Iterativa, a limiarização adaptativa média, a limiarização adaptativa gaussiana e a limiarização global simples.
Segmentação de regiões
Como descrito no começo do post, o objetivo da segmentação é dividir a imagem em regiões e a seguir serão apresentadas as técnicas usadas com esse objetivo.
A primeira técnica apresentada é a técnica de segmentação por crescimento de região. Os métodos de segmentação baseados em região visam reunir em um mesmo conjunto, pixels adjacentes que atendem a um dado critério de diversidade. Desta forma, regiões da imagem são agrupadas ou divididas, dependendo de seus pixels terem ou não características semelhantes em termos de cor, textura ou forma.
Está técnica necessita de ao menos duas informações, uma limiar de similaridade e um conjunto de locais/pontos inicias, que serão utilizados para começar o agrupamento. Para ilustrar, observe a matriz da Figura 8.a, nela foram selecionados 4 pontos de forma aleatória, para iniciar o processo de agrupamento de região. Após selecionar os locais iniciais, foi comparada a vizinhança destes pontos com uma limiar de tamanho 2, caso o valor seja uma diferença igual a este tamanho, a vizinhança será agrupada, conforme ilustra a Figura 8.c. Este processo é repetido até percorrer todos os locais da Imagem.

Neste tipo de técnica existem dois grandes problemas, que são os problemas de todas as técnicas de segmentação, que são: identificar quantos pontos iniciais serão utilizados, ou qual nível/profundidade de segmentação é desejada, e qual o critério ou limiar de similaridade que devemos utilizar.
Observe na Figura 8.d que possuímos também um terceiro problema, que os valores 3 da matriz, não foram agrupados ainda. Porém, dependendo da ordem de processamento, estes valores poderiam ser agrupados com os valores 1 ou com os valores 5, conforme demonstrado nas figuras 8.g e 8.h. Para piorar a situação, talvez o ideal fosse que estes valores estivessem segmentados em uma única região, se tivesse sido iniciado o processo de segmentação com um ponto inicial a mais.
Uma outra técnica é a técnica de divisor de águas Watershed. O método de segmentação calcula o gradiente para todos os pixels da imagem. Imagine que os valores de gradiente formem uma superfície topográfica com vales e montanhas. As regiões mais baixas, conforme Figura 9.c seriam correspondentes as de menor gradiente e as mais altas as de maior gradiente. Os crescimentos de regiões seriam equivalentes a uma inundação feita a partir da abertura de um pequeno furo nas regiões mais baixas. Os segmentos seriam formados por regiões conforme se formam bacias hidrográficas, daí o nome divisor de águas.

E uma última técnica muito interessante, é a segmentação por movimento. O conceito desta técnica é simples, através da análise do deslocamento dos objetos são extraídas as regiões de interessa da imagem. Este tipo de técnica é uma ferramenta poderosa de segmentação em ambiente abertos e cenários não controlados. Não existe uma solução única ou genérica para esta técnica, mas existem diversos trabalhos na literatura com esse objetivo. Abaixo são demostrados os resultados de dois artigos a fim de ilustrar a técnica.


Todas estas técnicas descritas até então, são técnicas que segmentam imagem sem rotulação, ou seja, como resultado da sua aplicação não se sabe o que é o objeto segmentado. A seguir será discutido brevemente o conceito de classificação de imagem, que tem com objetivo rotular a imagem.
Classificação, Detecção e Identificação de objetos
A classificação de padrões ou imagens, visa determinar um mapeamento que relacione as propriedade extraídas de amostras com um conjunto de rótulos, e ao atribuir um mesmo rótulo a amostras distintas, diz-se que tais elementos pertencem a uma mesma classe [PS].
O conceito de classificação está relacionado ao aprendizado de máquina, reconhecimento de padrões e inteligência artificial (IA) que se baseiam na ideia de que sistemas podem aprender com dados, identificar padrões e tomar decisões para uma variedades de possibilidades. Para simplificar, vamos nos limitar a ideia e ao conceito de classificar imagens através de rótulos, para identificar esse rótulos e detectar algo em outras imagens e vídeos.
Antes de prosseguir, saiba que o conceito de classificação não é considerado parte da área de segmentação de imagens, porém é muito utilizado para este fim, com diversas soluções para segmentar imagens.
Agora, vamos analisar o segundo cenário novamente, onde temos a imagem da vista de um carro para a rua e nela queremos identificar pedestres, carros e sinais de trânsito. Para isto, precisamos ao menos realizar três etapas: criar e coletar uma base de imagens, treinar algum algoritmos de classificação e utilizar o algoritmo treinado para classificar outras imagens.
A tarefa de criação de base de dados é a mais simples das três tarefas, porém muito onerosa, pois demanda muito tempo para se criar uma base de dados e dependendo da precisão desejada essa tarefa se torna uma tarefa continua. Para o cenário 2, a base de dados deve ser criada com no mínimo três informações: a imagens com o que se deseja rotular, a localização de todos os objetos de interesse na imagem para todas as imagens e o nome do rótulo. Dependendo do algoritmo, mais informações são necessárias.
A segunda tarefa de treinamento, de modo geral, consiste em informar a base de dados para ser treinada no algoritmo e aguardar seu treinamento. Esta tarefa costuma ser demorada para ser finalizada, pois exige muito processamento do computador, podendo levar horas ou dias. Caso não se tenha um computador com uma placa de vídeo, é recomendado que a tarefa seja feita em algum computador na nuvem que a tenha.
A última etapa, consiste em utilizar o algoritmo treinado para identificar os rótulas na imagem. Estas três etapas são mais complexas do que isso que foi exposto, porém a ideia geral das técnicas de classificação é essa.
Na Figura 12 é apresentado o resultado do algoritmo YOLO – You Only Look Once, que significa “Você só olha uma vez”. A ideia do YOLO é que ao receber uma imagem a ser rotulada, ele consiga identificar todos os rótulos treinados de uma única vez.

O que “identificar todos os rótulos de uma única vez” quer dizer? Bom, para explicar isso, antes vamos precisar entender outro tipo de técnica. Observe na Figura 13 a ilustração de uma RNA – Rede Neural Artificial, técnica de IA inspirada no sistema nervoso central de um animal (em particular o cérebro). Esta rede neural foi treinada como objetivo de identificar, se na imagem existe um cachorro, um gato ou nenhum dos dois.
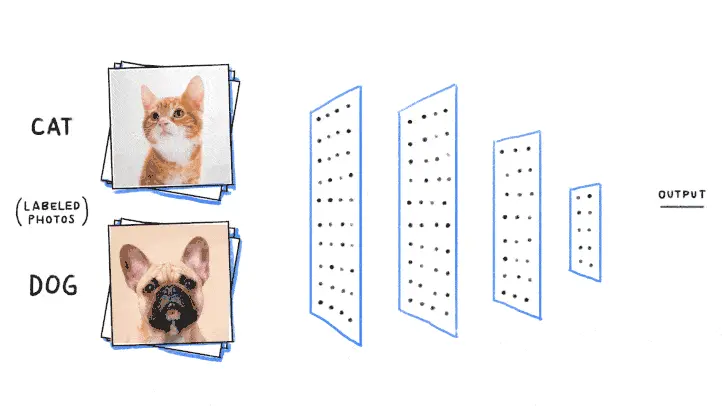
Porém, esta rede neural ilustrativa, foi criada de tal forma que só é possível confirmar se na imagem possuir apenas um gato ou um cachorro, caso a imagem possuir mais de um gato, ou um gato e um cachorro, por exemplo, ela não saberá identificar. Para resolver este tipo de problema, boa parte das técnicas de classificação tem como solução, percorrer a imagem em regiões menores, testando cada parte da imagem, a fim de identificar a existência de objetos rotulados, e localizar sua posição, conforme ilustra a figura abaixo.

De volta ao YOLO, sua diferença com a técnica apresentada anteriormente, é que sua mecânica não necessita percorrer a imagem em regiões menores para identificar mais de um rótulo ou objeto, pois utilizando toda a região da imagem ele consegue identificar tantos objetos, quanto sua etapa de treinamento o ensinou. Porém, não quer dizer que dividir a imagem em regiões menores, também não possa ser feito com o YOLO, mas então entraríamos em outras questões, como performance, precisão e técnicas de treinamento.
Existem diversas técnicas de classificação de imagem para rotulação, que utilizam estes dois conceitos apresentados, cada uma com sua característica e vantagem, abaixo trago algumas conhecidas:
- R-CNN – Region-based Convolutional Neural Networks
- SPP-net – Spatial Pyramid Pooling
- Fast R-CNN
- Faster R-CNN
- SSD – Single Shot Detector
- R-FCN
Além das técnicas de classificação, para rotulação de objetos conhecidos, existem diversos estudos que utilizam IA para segmentar a imagem em regiões, conforme descrito no cenário 1 e não foram apresentadas neste post para não delongá-lo, pois seu objeto é transmitir uma visão geral sobre segmentação de imagens.
Caso tenha dúvidas ou sugestões de melhorias no post, deixe seu comentário abaixo.
Referencias:
[GW] GONZALEZ, R. C., WOODS, R. E. Processamento de Imagens Digitais. Editora Edgard Blucher, ISBN 978-85-8143-586-2, 3 ed., São Paulo, 2010
[PS] Pedrini, H.; Schwartz, W. R.; Análise de Imagens Digitais: Princípios, Algoritmos e Aplicações. Thomson Learning, 2007
[MSBTV] M. Keuper, S. Tang, B. Andres, T. Brox and B. Schiele, “Motion Segmentation & Multiple Object Tracking by Correlation Co-Clustering” in IEEE Transactions on Pattern Analysis & Machine Intelligence, vol. 42, no. 01, pp. 140-153, 2020.
doi: 10.1109/TPAMI.2018.2876253
[VJ] Vertens, Johan et al. “SMSnet: Semantic motion segmentation using deep convolutional neural networks.” 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (2017): 582-589.
[VT] Venkatesh Tata. Simple Image Classification using Convolutional Neural Network — Deep Learning in python. Acessado em 14/04/2022.
[DK] Darknet. YOLO: Real-Time Object Detection. Acessado em 15/04/2022.

